

I recently gave a lecture on the benefits of building non-blocking processes. This is a write-up of the full talk, minus any “ums” that may have occurred.
I’ve been helping out a group called the Open Web Application Security Project (OWASP). They’re a non-profit foundation that produces some of the foremost application testing guides and cybersecurity resources. OWASP’s publications, checklists, and reference materials are a help to security professionals, penetration testers, and developers all over the world. Most of the individual teams that create these materials are run almost entirely by volunteers.
OWASP is a great group doing important work. I’ve seen this firsthand as part of the core team that produces the Web Security Testing Guide. However, while OWASP inspires in its large volunteer base, it lacks in the area of central organization.
This lack of organization was most recently apparent in the group’s website, OWASP.org. A big organization with an even bigger website to match, OWASP.org enjoys hundreds of thousands of visitors. Unfortunately, many of its pages - individually managed by disparate projects - are infrequently updated. Some are abandoned. The website as a whole lacks a centralized quality assurance process, and as a result, OWASP.org is peppered with broken links.
The trouble with broken links
Customers don’t like broken links; attackers really do. That’s because broken links are a security vulnerability. Broken links can signal opportunities for attacks like broken link hijacking and subdomain takeovers. At their least effective, these attacks can be embarrassing; at their worst, severely damaging to businesses and organizations. One OWASP group, the Application Security Verification Standard (ASVS) project, writes about integrity controls that can help to mitigate the likelihood of these attacks. This knowledge, unfortunately, has not yet propagated throughout the rest of OWASP yet.
This is the story of how I created a fast and efficient tool to help OWASP solve this problem.
The job
I took on the task of creating a program that could run as part of a CI/CD process to detect and report broken links. The program needed to:
- Find and enumerate all the broken links on OWASP.org in a report.
- Keep track of the parent pages the broken links were on so they could be fixed.
- Run efficiently as part of a CI/CD pipeline.
Essentially; I need to build a web crawler.
My original journey through this process was also in Python, as that was a comfortable language choice for everyone in the OWASP group. Personally, I prefer to use Go for higher performance as it offers more convenient concurrency primitives. Between the task and this talk, I wrote three programs: a prototype single-thread Python program, a multithreaded Python program, and a Go program using goroutines. We’ll see a comparison of how each worked out near the end of the talk - first, let’s explore how to build a web crawler.
Prototyping a web crawler
Here’s what our web crawler will need to do:
- Get the HTML data of the first page of the website (for example,
https://victoria.dev) - Check all of the links on the page
- Keep track of the links we’ve already visited so we don’t end up checking them twice
- Record any broken links we find
- Fetch more HTML data from any valid links on the page, as long as they’re in the same domain (
https://victoria.devand nothttps://github.com, for instance) - Repeat step #2 until all of the links on the site have been checked
Here’s what the execution flow will look like:
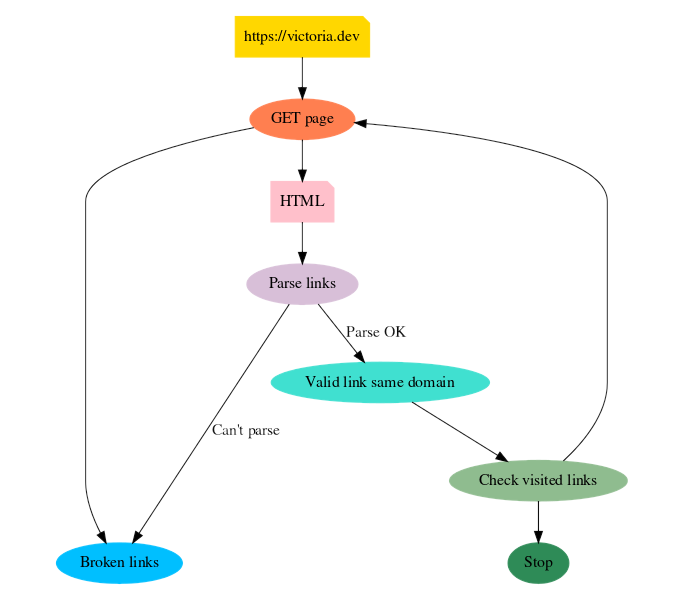
As you can see, the nodes “GET page” -> “HTML” -> “Parse links” -> “Valid link” -> “Check visited” all form a loop. These are what enable our web crawler to continue crawling until all the links on the site have been accounted for in the “Check visited” node. When the crawler encounters links it’s already checked, it will “Stop.” This loop will become more important in a moment.
For now, the question on everyone’s mind (I hope): how do we make it fast?
How fast can you do the thing
Here are some approximate timings for tasks performed on a typical PC:
| Type | Task | Time |
|---|---|---|
| CPU | execute typical instruction | 1/1,000,000,000 sec = 1 nanosec |
| CPU | fetch from L1 cache memory | 0.5 nanosec |
| CPU | branch misprediction | 5 nanosec |
| CPU | fetch from L2 cache memory | 7 nanosec |
| RAM | Mutex lock/unlock | 25 nanosec |
| RAM | fetch from main memory | 100 nanosec |
| RAM | read 1MB sequentially from memory | 250,000 nanosec |
| Disk | fetch from new disk location (seek) | 8,000,000 nanosec (8ms) |
| Disk | read 1MB sequentially from disk | 20,000,000 nanosec (20ms) |
| Network | send packet US to Europe and back | 150,000,000 nanosec (150ms) |
Peter Norvig first published these numbers some years ago in Teach Yourself Programming in Ten Years. They typically crop up now and then in articles titled along the lines of, “Latency numbers every developer should know.”
Since computers and their components change year over year, the exact numbers shown above aren’t the point. What these numbers help to illustrate is the difference, in orders of magnitude, between operations.
Compare the difference between fetching from main memory and sending a simple packet over the Internet. While both these operations occur in less than the blink of an eye (literally) from a human perspective, you can see that sending a simple packet over the Internet is over a million times slower than fetching from RAM. It’s a difference that, in a single-thread program, can quickly accumulate to form troublesome bottlenecks.
Bottleneck: network latency
The numbers above mean that the difference in time it takes to send something over the Internet compared to fetching data from main memory is over six orders of magnitude. Remember the loop in our execution chart? The “GET page” node, in which our crawler fetches page data over the network, is going to be a million times slower than the next slowest thing in the loop!
We don’t need to run our prototype to see what that means in practical terms; we can estimate it. Let’s take OWASP.org, which has upwards of 12,000 links, as an example:
150 milliseconds
x 12,000 links
---------
1,800,000 milliseconds (30 minutes)
A whole half hour, just for the network tasks. It may even be much slower than that, since web pages are frequently much larger than a packet. This means that in our single-thread prototype web crawler, our biggest bottleneck is network latency. Why is this problematic?
Feedback loops
I previously wrote about feedback loops. In essence, in order to improve at doing anything, you first need to be able to get feedback from your last attempt. That way, you have the necessary information to make adjustments and get closer to your goal on your next iteration.
As a software developer, bottlenecks can contribute to long and inefficient feedback loops. If I’m waiting on a process that’s part of a CI/CD pipeline, in our bottlenecked web crawler example, I’d be sitting around for a minimum of a half hour before learning whether or not changes in my last push were successful, or whether they broke master (hopefully staging).
Multiply a slow and inefficient feedback loop by many runs per day, over many days, and you’ve got a slow and inefficient developer. Multiply that by many developers in an organization bottlenecked on the same process, and you’ve got a slow and inefficient company.
The cost of bottlenecks
To add insult to injury, not only are you waiting on a bottlenecked process to run; you’re also paying to wait. Take the serverless example - AWS Lambda, for instance. Here’s a chart showing the cost of functions by compute time and CPU usage.
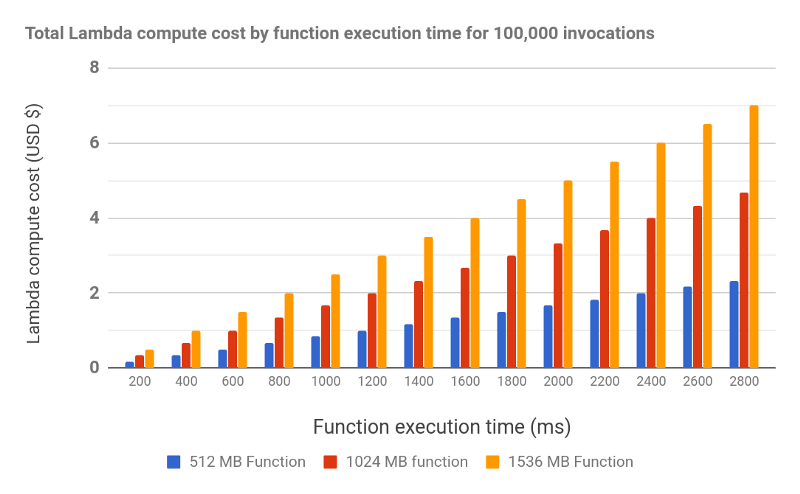
Again, the numbers change over the years, but the main concepts remain the same: the bigger the function and the longer its compute time, the bigger the cost. For applications taking advantage of serverless, these costs can add up dramatically.
Bottlenecks are a recipe for failure, for both productivity and the bottom line.
The good news is that bottlenecks are mostly unnecessary. If we know how to identify them, we can strategize our way out of them. To understand how, let’s get some tacos.
Tacos and threading
Everyone, meet Bob. He’s a gopher who works at the taco stand down the street as the cashier. Say “Hi,” Bob.
🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮
🌮 🌳
🌮
🌮 ╔══════════════╗
🌮 Hi I'm Bob 🌳
🌮 ╚══════════════╝ \
🌮 🐹 🌮
🌮
🌮
🌮 🌳
🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮
Bob works very hard at being a cashier, but he’s still just one gopher. The customers who frequent Bob’s taco stand can eat tacos really quickly; but in order to get the tacos to eat them, they’ve got to order them through Bob. Here’s what our bottlenecked, single-thread taco stand currently looks like:
🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮
🌮 🌳
🌮
🌮
🌮 🌳
🌮 🐹 🧑💵🧑💵🧑💵🧑💵🧑💵🧑💵🧑💵🧑💵🧑💵
🌮
🌮
🌮
🌮 🌳
🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮
As you can see, all the customers are queued up, right out the door. Poor Bob handles one customer’s transaction at a time, starting and finishing with that customer completely before moving on to the next. Bob can only do so much, so our taco stand is rather inefficient at the moment. How can we make Bob faster?
We can try splitting the queue:
🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮
🌮 🌳
🌮
🌮 🧑💵🧑💵🧑💵🧑💵
🌮 🌳
🌮 🐹
🌮
🌮 🧑💵🧑💵🧑💵🧑💵🧑💵
🌮
🌮 🌳
🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮
Now Bob can do some multitasking. For example, he can start a transaction with a customer in one queue; then, while that customer counts their bills, Bob can pop over to the second queue and get started there. This arrangement, known as a concurrency model, helps Bob go a little bit faster by jumping back and forth between lines. However, it’s still just one Bob, which limits our improvement possibilities. If we were to make four queues, they’d all be shorter; but Bob would be very thinly stretched between them. Can we do better?
We could get two Bobs:
🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮
🌮 🌳
🌮
🌮 🌳
🌮 🐹 🧑💵🧑💵🧑💵🧑💵
🌮 🌳
🌮 🐹 🧑💵🧑💵🧑💵🧑💵🧑💵
🌮 🌳
🌮
🌮 🌳
🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮
With twice the Bobs, each can handle a queue of his own. This is our most efficient solution for our taco stand so far, since two Bobs can handle much more than one Bob can, even if each customer is still attended to one at a time.
We can do even better than that:
🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮
🌮 🌳
🌮 🐹 🧑💵🧑💵
🌮 🌳
🌮 🐹 🧑💵🧑💵
🌮 🌳
🌮 🐹 🧑💵🧑💵
🌮 🌳
🌮 🐹 🧑💵🧑💵🧑💵
🌮 🌳
🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮🌮
With quadruple the Bobs, we have some very short queues, and a much more efficient taco stand. In computing, the concept of having multiple workers do tasks in parallel is called multithreading.
In Go, we can apply this concept using goroutines. Here are some illustrative snippets from my Go solution.
Setting up a Go web crawler
In order to share data between our goroutines, we’ll need to create some data structures. Our Checker structure will be shared, so it will have a Mutex (mutual exclusion) to allow our goroutines to lock and unlock it. The Checker structure will also hold a list of brokenLinks results, and visitedLinks. The latter will be a map of strings to booleans, which we’ll use to directly and efficiently check for visited links. By using a map instead of iterating over a list, our visitedLinks lookup will have a constant complexity of O(1) as opposed to a linear complexity of O(n), thus avoiding the creation of another bottleneck. For more on time complexity, see my coffee-break introduction to time complexity of algorithms article.
type Checker struct {
startDomain string
brokenLinks []Result
visitedLinks map[string]bool
workerCount, maxWorkers int
sync.Mutex
}
...
// Page allows us to retain parent and sublinks
type Page struct {
parent, loc, data string
}
// Result adds error information for the report
type Result struct {
Page
reason string
code int
}
To extract links from HTML data, here’s a parser I wrote on top of package html:
// Extract links from HTML
func parse(parent, data string) ([]string, []string) {
doc, err := html.Parse(strings.NewReader(data))
if err != nil {
fmt.Println("Could not parse: ", err)
}
goodLinks := make([]string, 0)
badLinks := make([]string, 0)
var f func(*html.Node)
f = func(n *html.Node) {
if n.Type == html.ElementNode && checkKey(string(n.Data)) {
for _, a := range n.Attr {
if checkAttr(string(a.Key)) {
j, err := formatURL(parent, a.Val)
if err != nil {
badLinks = append(badLinks, j)
} else {
goodLinks = append(goodLinks, j)
}
break
}
}
}
for c := n.FirstChild; c != nil; c = c.NextSibling {
f(c)
}
}
f(doc)
return goodLinks, badLinks
}
If you’re wondering why I didn’t use a more full-featured package for this project, I highly recommend the story of left-pad. The short of it: more dependencies, more problems.
Here are snippets of the main function, where we pass in our starting URL and create a queue (or channels, in Go) to be filled with links for our goroutines to process.
func main() {
...
startURL := flag.String("url", "http://example.com", "full URL of site")
...
firstPage := Page{
parent: *startURL,
loc: *startURL,
}
toProcess := make(chan Page, 1)
toProcess <- firstPage
var wg sync.WaitGroup
The last significant piece of the puzzle is to create our workers, which we’ll do here:
for i := range toProcess {
wg.Add(1)
checker.addWorker()
🐹 go worker(i, &checker, &wg, toProcess)
if checker.workerCount > checker.maxWorkers {
time.Sleep(1 * time.Second) // throttle down
}
}
wg.Wait()
A WaitGroup does just what it says on the tin: it waits for our group of goroutines to finish. When they have, we’ll know our Go web crawler has finished checking all the links on the site.
Did we do the thing fast
Here’s a comparison of the three programs I wrote on this journey. First, the prototype single-thread Python version:
time python3 slow-link-check.py https://victoria.dev
real 17m34.084s
user 11m40.761s
sys 0m5.436s
This finished crawling my website in about seventeen-and-a-half minutes, which is rather long for a site at least an order of magnitude smaller than OWASP.org.
The multithreaded Python version did a bit better:
time python3 hydra.py https://victoria.dev
real 1m13.358s
user 0m13.161s
sys 0m2.826s
My multithreaded Python program (which I dubbed Hydra) finished in one minute and thirteen seconds.
How did Go do?
time ./go-link-check --url=https://victoria.dev
real 0m7.926s
user 0m9.044s
sys 0m0.932s
At just under eight seconds, I found the Go version to be extremely palatable.
Breaking bottlenecks
As fun as it is to simply enjoy the speedups, we can directly relate these results to everything we’ve learned so far. Consider taking a process that used to soak up seventeen minutes and turning it into an eight-second-affair instead. Not only will that give developers a much shorter and more efficient feedback loop, it will give companies the ability to develop faster, and thus grow more quickly - while costing less. To drive the point home: a process that runs in seventeen-and-a-half minutes when it could take eight seconds will also cost over a hundred and thirty times as much to run!
A better work day for developers, and a better bottom line for companies. There’s a lot of benefit to be had in making functions, code, and processes as efficient as possible - by breaking bottlenecks.
computing ci/cd coding cybersecurity go python