Algorithms on victoria.dev2023-09-26T04:46:36-05:00https://victoria.dev/tags/algorithms/Victoria Drakehello@victoria.devHugo -- gohugo.ioHow to send long text input to ChatGPT using the OpenAI APIhttps://victoria.dev/blog/how-to-send-long-text-input-to-chatgpt-using-the-openai-api/Victoria Drake2023-09-26T04:46:36-05:002023-09-26T04:46:36-05:00In a previous post, I showed how you can apply text preprocessing techniques to shorten your input length for ChatGPT. Today in the web interface (chat.openai.com), ChatGPT allows you to send a message with a maximum token length of 4,096.
There are bound to be situations in which this isn’t enough, such as when you want to read in a large amount of text from a file. Using the OpenAI API allows you to send many more tokens in a messages array, with the maximum number depending on your chosen model. This lets you provide large amounts of text to ChatGPT using chunking. Here’s how.
The gpt-4 model currently has a maximum content length token limit of 8,192 tokens. (Here are the docs containing current limits for all the models.) Remember that you can first apply text preprocessing techniques to reduce your input size – in my previous post I achieved a 28% size reduction without losing meaning with just a little tokenization and pruning.
When this isn’t enough to fit your message within the maximum message token limit, you can take a general programmatic approach that sends your input in message chunks. The goal is to divide your text into sections that each fit within the model’s token limit. The general idea is to:
Tokenize and split text into chunks based on the model’s token limit. It’s better to keep message chunks slightly below the token limit since the token limit is shared between your message and ChatGPT’s response.
Maintain context between chunks, e.g. avoid splitting a sentence in the middle.
Each chunk is sent as a separate message in the conversation thread.
You send your chunks to ChatGPT using the OpenAI library’s ChatCompletion. ChatGPT returns individual responses for each message, so you may want to process these by:
Concatenating responses in the order you sent them to get a coherent answer.
Manage conversation flow by keeping track of which response refers to which chunk.
Formatting the response to suit your desired output, e.g. replacing \n with line breaks.
Using the OpenAI API, you can send multiple messages to ChatGPT and ask it to wait for you to provide all of the data before answering your prompt. Being a language model, you can provide these instructions to ChatGPT in plain language. Here’s a suggested script:
Prompt: Summarize the following text for me
To provide the context for the above prompt, I will send you text in parts. When I am finished, I will tell you “ALL PARTS SENT”. Do not answer until you have received all the parts.
I created a Python module, chatgptmax, that puts all this together. It breaks up a large amount of text by a given maximum token length and sends it in chunks to ChatGPT.
You can install it with pip install chatgptmax, but here’s the juicy part:
importosimportopenaiimporttiktoken# Set up your OpenAI API key# Load your API key from an environment variable or secret management serviceopenai.api_key=os.getenv("OPENAI_API_KEY")defsend(prompt=None,text_data=None,chat_model="gpt-3.5-turbo",model_token_limit=8192,max_tokens=2500,):"""
Send the prompt at the start of the conversation and then send chunks of text_data to ChatGPT via the OpenAI API.
If the text_data is too long, it splits it into chunks and sends each chunk separately.
Args:
- prompt (str, optional): The prompt to guide the model's response.
- text_data (str, optional): Additional text data to be included.
- max_tokens (int, optional): Maximum tokens for each API call. Default is 2500.
Returns:
- list or str: A list of model's responses for each chunk or an error message.
"""# Check if the necessary arguments are providedifnotprompt:return"Error: Prompt is missing. Please provide a prompt."ifnottext_data:return"Error: Text data is missing. Please provide some text data."# Initialize the tokenizertokenizer=tiktoken.encoding_for_model(chat_model)# Encode the text_data into token integerstoken_integers=tokenizer.encode(text_data)# Split the token integers into chunks based on max_tokenschunk_size=max_tokens-len(tokenizer.encode(prompt))chunks=[token_integers[i:i+chunk_size]foriinrange(0,len(token_integers),chunk_size)]# Decode token chunks back to stringschunks=[tokenizer.decode(chunk)forchunkinchunks]responses=[]messages=[{"role":"user","content":prompt},{"role":"user","content":"To provide the context for the above prompt, I will send you text in parts. When I am finished, I will tell you 'ALL PARTS SENT'. Do not answer until you have received all the parts.",},]forchunkinchunks:messages.append({"role":"user","content":chunk})# Check if total tokens exceed the model's limit and remove oldest chunks if necessarywhile(sum(len(tokenizer.encode(msg["content"]))formsginmessages)>model_token_limit):messages.pop(1)# Remove the oldest chunkresponse=openai.ChatCompletion.create(model=chat_model,messages=messages)chatgpt_response=response.choices[0].message["content"].strip()responses.append(chatgpt_response)# Add the final "ALL PARTS SENT" messagemessages.append({"role":"user","content":"ALL PARTS SENT"})response=openai.ChatCompletion.create(model=chat_model,messages=messages)final_response=response.choices[0].message["content"].strip()responses.append(final_response)returnresponses
Here’s an example of how you can use this module with text data read from a file. (chatgptmax also provides a convenience method for getting text from a file.)
# First, import the necessary modules and the functionimportosfromchatgptmaximportsend# Define a function to read the content of a filedefread_file_content(file_path):withopen(file_path,'r',encoding='utf-8')asfile:returnfile.read()# Use the functionif__name__=="__main__":# Specify the path to your filefile_path="path_to_your_file.txt"# Read the content of the filefile_content=read_file_content(file_path)# Define your promptprompt_text="Summarize the following text for me:"# Send the file content to ChatGPTresponses=send(prompt=prompt_text,text_data=file_content)# Print the responsesforresponseinresponses:print(response)
While the module is designed to handle most standard use cases, there are potential pitfalls to be aware of:
Incomplete sentences: If a chunk ends in the middle of a sentence, it might alter the meaning or context. To mitigate this, consider ensuring that chunks end at full stops or natural breaks in the text. You could do this by separating the text-chunking task into a separate function that:
Splits the text into sentences.
Iterates over the sentences and adds them to a chunk until the chunk reaches the maximum size.
Starts a new chunk when the current chunk reaches the maximum size or when adding another sentence would exceed the maximum size.
API connectivity issues: There’s always a possibility of timeouts or connectivity problems during API calls. If this is a significant issue for your application, you can include retry logic in your code. If an API call fails, the script could wait for a few seconds and then try again, ensuring that all chunks are processed.
Rate limits: Be mindful of OpenAI API’s rate limits. If you’re sending many chunks in rapid succession, you might hit these limits. Introducing a slight delay between calls or spreading out requests can help avoid this.
As with any process, there’s always room for improvement. Here are a couple of ways you might optimize the module’s chunking and sending process further:
Parallelizing API calls: If OpenAI API’s rate limits and your infrastructure allow, you could send multiple chunks simultaneously. This parallel processing can speed up the overall time it takes to get responses for all chunks. Unless you have access to OpenAI’s 32k models or need to use small chunk sizes, however, parallelism gains are likely to be minimal.
Caching mechanisms: If you find yourself sending the same or similar chunks frequently, consider implementing a caching system. By storing ChatGPT’s responses for specific chunks, you can retrieve them instantly from the cache the next time, saving both time and API calls.
If you found your way here via search, you probably already have a use case in mind. Here are some other (startup) ideas:
You’re a researcher who wants to save time by getting short summaries of many lengthy articles.
You’re a legal professional who wants to analyze long contracts by extracting key points or clauses.
You’re a financial analyst who wants to pull a quick overview of trends from a long report.
You’re a writer who wants feedback on a new article or chapter… without having to actually show it to anyone yet.
Do you have a use case I didn’t list? Let me know about it! In the meantime, have fun sending lots of text to ChatGPT.
]]>Optimizing text for ChatGPT: NLP and text pre-processing techniqueshttps://victoria.dev/blog/optimizing-text-for-chatgpt-nlp-and-text-pre-processing-techniques/Victoria Drake2023-09-19T04:46:36-05:002023-09-19T04:46:36-05:00In order for chatbots and voice assistants to be helpful, they need to be able to take in and understand our instructions in plain language using Natural Language Processing (NLP). ChatGPT relies on a blend of advanced algorithms and text preprocessing methods to make sense of our words. But just throwing a wall of text at it can be inefficient – you might be dumping in a lot of noise with that signal and hitting the text input limit.
Text preprocessing can help shorten and refine your input, ensuring that ChatGPT can grasp the essence without getting overwhelmed. In this article, we’ll explore these techniques, understand their importance, and see how they make your interactions with tools like ChatGPT more reliable and productive.
Text preprocessing prepares raw text data for analysis by NLP models. Generally, it distills everyday text (like full sentences) to make it more manageable or concise and meaningful. Techniques include:
Tokenization: splitting up text by sentences or paragraphs. For example, you could break down a lengthy legal document into individual clauses or sentences.
Extractive summarization: selecting key sentences from the text and discarding the rest. Instead of reading an entire 10-page document, extractive summarization could pinpoint the most crucial sentences and give you a concise overview without delving into the details.
Abstractive summarization: generating a concise representation of the text content, for example, turning a 10-page document into a brief paragraph that captures the document’s essence in new wording.
Pruning: removing redundant or less relevant parts. For example, in a verbose email thread, pruning can help remove all the greetings, sign-offs, and other repetitive elements, leaving only the core content for analysis.
While all these techniques can help reduce the size of raw text data, some of these techniques are easier to apply to general use cases than others. Let’s examine how text preprocessing can help us send a large amount of text to ChatGPT.
In the realm of Natural Language Processing (NLP), a token is the basic unit of text that a system reads. At its simplest, you can think of a token as a word, but depending on the language and the specific tokenization method used, a token can represent a word, part of a word, or even multiple words.
While in English we often equate tokens with words, in NLP, the concept is broader. A token can be as short as a single character or as long as a word. For example, with word tokenization, the sentence “Unicode characters such as emojis are not indivisible. ✂️” can be broken down into tokens like this: [“Unicode”, “characters”, “such”, “as”, “emojis”, “are”, “not”, “indivisible”, “.”, “✂️”]
In another form called Byte-Pair Encoding (BPE), the same sentence is tokenized as: [“Un”, “ic”, “ode”, " characters", " such", " as", " em, “oj”, “is”, " are", " not", " ind", “iv”, “isible”, “.”, " �", “�️”]. The emoji itself is split into tokens containing its underlying bytes.
Depending on the ChatGPT model chosen, your text input size is restricted by tokens. Here are the docs containing current limits. BPE is used by ChatGPT to determine token count, and we’ll discuss it more thoroughly later. First, we can programmatically apply some preprocessing techniques to reduce our text input size and use fewer tokens.
For a general approach that can be applied programmatically, pruning is a suitable preprocessing technique. One form is stop word removal, or removing common words that might not add significant meaning in certain contexts. For example, consider the sentence:
“I always enjoy having pizza with my friends on weekends.”
Stop words are often words that don’t carry significant meaning on their own in a given context. In this sentence, words like “I”, “always”, “enjoy”, “having”, “with”, “my”, “on” are considered stop words.
After removing the stop words, the sentence becomes:
“pizza friends weekends.”
Now, the sentence is distilled to its key components, highlighting the main subject (pizza) and the associated context (friends and weekends). If you find yourself wishing you could convince people to do this in real life (coughmeetingscough)… you aren’t alone.
Stop word removal is straightforward to apply programmatically: given a list of stop words, examine some text input to see if it contains any of the stop words on your list. If it does, remove them, then return the altered text.
To see how effective stop word removal can be, I took the entire text of my Tech Leader Docs newsletter (17,230 words consisting of 104,892 characters) and processed it using the above function. How effective was it? The resulting text contained 89,337 characters, which is about a 15% reduction in size.
Other pruning techniques can also be applied programmatically. Removing punctuation, numbers, HTML tags, URLs and email addresses, or non-alphabetical characters are all valid pruning techniques that can be straightforward to apply. Here is a function that does just that:
importredefclean_text(text):# Remove URLstext=re.sub(r'http\S+','',text)# Remove email addressestext=re.sub(r'\S+@\S+','',text)# Remove everything that's not a letter (a-z, A-Z)text=re.sub(r'[^a-zA-Z\s]','',text)# Remove whitespace, tabs, and new linestext=''.join(text.split())returntext
What measure of length reduction might we be able to get from this additional processing? Applying these techniques to the remaining characters of Tech Leader Docs results in just 75,217 characters; an overall reduction of about 28% from the original text.
More opinionated pruning, such as removing short words or specific words or phrases, can be tailored to a specific use case. These don’t lend themselves well to general functions, however.
Now that you have some text processing techniques in your toolkit, let’s look at how a reduction in characters translates to fewer tokens used when it comes to ChatGPT. To understand this, we’ll examine Byte-Pair Encoding.
Byte-Pair Encoding (BPE) is a subword tokenization method. It was originally introduced for data compression but has since been adapted for tokenization in NLP tasks. It allows representing common words as tokens and splits more rare words into subword units. This enables a balance between character-level and word-level tokenization.
Let’s make that more concrete. Imagine you have a big box of LEGO bricks, and each brick represents a single letter or character. You’re tasked with building words using these LEGO bricks. At first, you might start by connecting individual bricks to form words. But over time, you notice that certain combinations of bricks (or characters) keep appearing together frequently, like “th” in “the” or “ing” in “running.”
BPE is like a smart LEGO-building buddy who suggests, “Hey, since ’th’ and ‘ing’ keep appearing together a lot, why don’t we glue them together and treat them as a single piece?” This way, the next time you want to build a word with “the” or “running,” you can use these glued-together pieces, making the process faster and more efficient.
Colloquially, the BPE algorithm looks like this:
Start with single characters.
Observe which pairs of characters frequently appear together.
Merge those frequent pairs together to treat them as one unit.
Repeat this process until you have a mix of single characters and frequently occurring character combinations.
BPE is a particularly powerful tokenization method, especially when dealing with diverse and extensive vocabularies. Here’s why:
Handling rare words: Traditional tokenization methods might stumble upon rare or out-of-vocabulary words. BPE, with its ability to break words down into frequent subword units, can represent these words without needing to have seen them before.
Efficiency: By representing frequent word parts as single tokens, BPE can compress text more effectively. This is especially useful for models like ChatGPT, where token limits apply.
Adaptability: BPE is language-agnostic. It doesn’t rely on predefined dictionaries or vocabularies. Instead, it learns from the data, making it adaptable to various languages and contexts.
In essence, BPE strikes a balance, offering the granularity of character-level tokenization and the context-awareness of word-level tokenization. This hybrid approach ensures that NLP models like ChatGPT can understand a wide range of texts while maintaining computational efficiency.
At time of writing, a message to ChatGPT via its web interface has a maximum token length of 4,096 tokens. If we assume the prior mentioned percent reduction as an average, this means you could reduce text of up to 5,712 tokens down to the appropriate size with just text preprocessing.
What about when this isn’t enough? Beyond text preprocessing, larger input can be sent in chunks using the OpenAI API. In my next post, I’ll show you how to build a Python module that does exactly that.
]]>WPA Key, WPA2, WPA3, and WEP Key: Wi-Fi security explainedhttps://victoria.dev/blog/wpa-key-wpa2-wpa3-and-wep-key-wi-fi-security-explained/Victoria Drake2020-10-19T04:02:27-04:002020-10-19T04:02:27-04:00Setting up new Wi-Fi? Picking the type of password you need can seem like an arbitrary choice. After all, WEP, WPA, WPA2, and WPA3 all have mostly the same letters in them. A password is a password, so what’s the difference?
About 60 seconds to billions of years, as it turns out.
All Wi-Fi encryption is not created equal. Let’s explore what makes these four acronyms so different, and how you can best protect your home and organization Wi-Fi.
Not to be confused with the name of a certain rap song.
Wired Equivalent Privacy is a deprecated security algorithm from 1997 that was intended to provide equivalent security to a wired connection. “Deprecated” means, “Let’s not do that anymore.”
Even when it was first introduced, it was known not to be as strong as it could have been, for two reasons: one, its underlying encryption mechanism; and two, World War II.
During World War II, the impact of code breaking (or cryptanalysis) was huge. Governments reacted by attempting to keep their best secret-sauce recipes at home. Around the time of WEP, U.S. Government restrictions on the export of cryptographic technology caused access point manufacturers to limit their devices to 64-bit encryption. Though this was later lifted to 128-bit, even this form of encryption offered a very limited possible key size.
This proved problematic for WEP. The small key size resulted in being easier to brute-force, especially when that key doesn’t often change.
WEP’s underlying encryption mechanism is the RC4 stream cipher. This cipher gained popularity due to its speed and simplicity, but that came at a cost. It’s not the most robust algorithm. WEP employs a single shared key among its users that must be manually entered on an access point device. (When’s the last time you changed your Wi-Fi password? Right.) WEP didn’t help matters either by simply concatenating the key with the initialization vector – which is to say, it sort of mashed its secret-sauce bits together and hoped for the best.
Combined with the use of RC4, this left WEP particularly susceptible to related-key attack. In the case of 128-bit WEP, your Wi-Fi password can be cracked by publicly-available tools in a matter of around 60 seconds to three minutes.
While some devices came to offer 152-bit or 256-bit WEP variants, this failed to solve the fundamental problems of WEP’s underlying encryption mechanism.
A new, interim standard sought to temporarily “patch” the problem of WEP’s (lack of) security. The name Wi-Fi Protected Access (WPA) certainly sounds more secure, so that’s a good start; however, WPA first started out with another, more descriptive name.
Ratified in a 2004 IEEE standard, Temporal Key Integrity Protocol (TKIP) uses a dynamically-generated, per-packet key. Each packet sent has a unique temporal 128-bit key, (See? Descriptive!) that solves the susceptibility to related-key attacks brought on by WEP’s shared key mashing.
TKIP also implements other measures, such as a message authentication code (MAC). Sometimes known as a checksum, a MAC provides a cryptographic way to verify that messages haven’t been changed. In TKIP, an invalid MAC can also trigger rekeying of the session key. If the access point receives an invalid MAC twice within a minute, the attempted intrusion can be countered by changing the key an attacker is trying to crack.
Unfortunately, in order to preserve compatibility with the existing hardware that WPA was meant to “patch,” TKIP retained the use of the same underlying encryption mechanism as WEP – the RC4 stream cipher. While it certainly improved on the weaknesses of WEP, TKIP eventually proved vulnerable to new attacks that extended previous attacks on WEP. These attacks take a little longer to execute by comparison: for example, twelve minutes in the case of one, and 52 hours in another. This is more than sufficient, however, to deem TKIP no longer secure.
WPA, or TKIP, has since been deprecated as well. So let’s also not do that anymore.
Rather than spend the effort to come up with an entirely new name, the improved Wi-Fi Protected Access II (WPA2) standard instead focuses on using a new underlying cipher. Instead of the RC4 stream cipher, WPA2 employs a block cipher called Advanced Encryption Standard (AES) to form the basis of its encryption protocol. The protocol itself, abbreviated CCMP, draws most of its security from the length of its rather long name (I’m kidding): Counter Mode Cipher Block Chaining Message Authentication Code Protocol, which shortens to Counter Mode CBC-MAC Protocol, or CCM mode Protocol, or CCMP. 🤷
CCM mode is essentially a combination of a few good ideas. It provides data confidentiality through CTR mode, or counter mode. To vastly oversimplify, this adds complexity to plaintext data by encrypting the successive values of a count sequence that does not repeat. CCM also integrates CBC-MAC, a block cipher method for constructing a MAC.
AES itself is on good footing. The AES specification was established in 2001 by the U.S. National Institute of Standards and Technology (NIST) after a five-year competitive selection process during which fifteen proposals for algorithm designs were evaluated. As a result of this process, a family of ciphers called Rijndael (Dutch) was selected, and a subset of these became AES. For the better part of two decades, AES has been used to protect every-day Internet traffic as well as certain levels of classified information in the U.S. Government.
While possible attacks on AES have been described, none have yet been proven to be practical in real-world use. The fastest attack on AES in public knowledge is a key-recovery attack that improved on brute-forcing AES by a factor of about four. How long would it take? Some billions of years.
The next installment of the WPA trilogy has been required for new devices since July 1, 2020. Expected to further enhance the security of WPA2, the WPA3 standard seeks to improve password security by being more resilient to word list or dictionary attacks.
Unlike its predecessors, WPA3 will also offer forward secrecy. This adds the considerable benefit of protecting previously exchanged information even if a long-term secret key is compromised. Forward secrecy is already provided by protocols like TLS by using asymmetric keys to establish shared keys. You can learn more about TLS in this post.
As WPA2 has not been deprecated, both WPA2 and WPA3 remain your top choices for Wi-Fi security.
You may be wondering why your access point even allows you to choose an option other than WPA2 or WPA3. The likely reason is that you’re using legacy hardware, which is what tech people call your mom’s router.
Since the deprecation of WEP and WPA occurred (in old-people terms) rather recently, it’s possible in large organizations as well as your parent’s house to find older hardware that still uses these protocols. Even newer hardware may have a business need to support these older protocols.
While I may be able to convince you to invest in a shiny new top-of-the-line Wi-Fi appliance, most organizations are a different story. Unfortunately, many just aren’t yet cognizant of the important role cybersecurity plays in meeting customer needs and boosting that bottom line. Additionally, switching to newer protocols may require new internal hardware or firmware upgrades. Especially on complex systems in large organizations, upgrading devices can be financially or strategically difficult.
If it’s an option, choose WPA2 or WPA3. Cybersecurity is a field that evolves by the day, and getting stuck in the past can have dire consequences.
If you can’t use WPA2 or WPA3, do the best you can to take additional security measures. The best bang for your buck is to use a Virtual Private Network (VPN). Using a VPN is a good idea no matter which type of Wi-Fi encryption you have. On open Wi-Fi (coffee shops) and using WEP, it’s plain irresponsible to go without a VPN. Kind of like shouting out your bank details as you order your second cappuccino.
When possible, ensure you only connect to known networks that you or your organization control. Many cybersecurity attacks are executed when victims connect to an imitation public Wi-Fi access point, also called an evil twin attack, or Wi-Fi phishing. These fake hotspots are easily created using publicly accessible programs and tools. A VPN can help mitigate damage from these attacks as well, but it’s always better not to take the risk. If you travel often, consider purchasing a portable hotspot that uses a cellular data plan, or using data SIM cards for all your devices.
WEP, WPA, WPA2, and WPA3 mean a lot more than a bunch of similar letters – in some cases, it’s a difference of billions of years minus about 60 seconds.
On more of a now-ish timescale, I hope I’ve taught you something new about the security of your Wi-Fi and how you can improve it!
]]>What is TLS? Transport Layer Security encryption explained in plain englishhttps://victoria.dev/blog/what-is-tls-transport-layer-security-encryption-explained-in-plain-english/Victoria Drake2020-09-05T04:48:39-06:002020-09-05T04:48:39-06:00If you want to have a confidential conversation with someone you know, you might meet up in person and find a private place to talk. If you want to send data confidentially over the Internet, you might have a few more considerations to cover.
TLS, or Transport Layer Security, refers to a protocol. “Protocol” is a word that means, “the way we’ve agreed to do things around here,” more or less. The “transport layer” part of TLS simply refers to host-to-host communication, such as how a client and a server interact, in the Internet protocol suite model.
The TLS protocol attempts to solve these fundamental problems:
How do I know you are who you say you are?
How do I know this message from you hasn’t been tampered with?
How can we communicate securely?
Here’s how TLS works, explained in plain English. As with many successful interactions, it begins with a handshake.
The basic process of a TLS handshake involves a client, such as your web browser, and a server, such as one hosting a website, establishing some ground rules for communication. It begins with the client saying hello. Literally. It’s called a ClientHello message.
The ClientHello message tells the server which TLS protocol version and cipher suites it supports. While “cipher suite” sounds like a fancy hotel upgrade, it just refers to a set of algorithms that can be used to secure communications. The server, in a similarly named ServerHello message, chooses the protocol version and cipher suite to use from the choices offered. Other data may also be sent, for example, a session ID if the server supports resuming a previous handshake.
Depending on the cipher suite chosen, the client and server exchange further information in order to establish a shared secret. Often, this process moves the exchange from asymmetric cryptography to symmetric cryptography with varying levels of complexity. Let’s explore these concepts at a general level and see why they matter to TLS.
Asymmetric cryptography is one method by which you can perform authentication. When you authenticate yourself, you answer the fundamental question, “How do I know you are who you say you are?”
In an asymmetric cryptographic system, you use a pair of keys in order to achieve authentication. These keys are asymmetric. One key is your public key, which, as you would guess, is public. The other is your private key, which – well, you know.
Typically, during the TLS handshake, the server will provide its public key via its digital certificate, sometimes still called its SSL certificate, though TLS replaces the deprecated Secure Sockets Layer (SSL) protocol. Digital certificates are provided and verified by trusted third parties known as Certificate Authorities (CA), which are a whole other article in themselves.
While anyone may encrypt a message using your public key, only your private key can then decrypt that message. The security of asymmetric cryptography relies only on your private key staying private, hence the asymmetry. It’s also asymmetric in the sense that it’s a one-way trip. Alice can send messages encrypted with your public key to you, but neither of your keys will help you send an encrypted message to Alice.
Asymmetric cryptography also requires more computational resources than symmetric cryptography. Thus when a TLS handshake begins with an asymmetric exchange, the client and server will use this initial communication to establish a shared secret, sometimes called a session key. This key is symmetric, meaning that both parties use the same shared secret and must maintain that secrecy for the encryption to be secure.
Wise man say: share your public key, but keep your shared keys private.
By using the initial asymmetric communication to establish a session key, the client and server can rely on the session key being known only to them. For the rest of the session, they’ll both use this same shared key to encrypt and decrypt messages, which speeds up communication.
A TLS handshake may use asymmetric cryptography or other cipher suites to establish the shared session key. Once the session key is established, the handshaking portion is complete and the session begins.
The session is the duration of encrypted communication between the client and server. During this time, messages are encrypted and decrypted using the session key that only the client and server have. This ensures that communication is secure.
The integrity of exchanged information is maintained by using a checksum. Messages exchanged using session keys have a message authentication code (MAC) attached. This is not the same thing as your device’s MAC address. The MAC is generated and verified using the session key. Because of this, either party can detect if a message has been changed before being received. This solves the fundamental question, “How do I know this message from you hasn’t been tampered with?”
Sessions can end deliberately, due to network disconnection, or from the client staying idle for too long. Once a session ends, it must be re-established via a new handshake or through previously established secrets called session IDs that allow resuming a session.
TLS is a cryptographic protocol for providing secure communication.
The process of creating a secure connection begins with a handshake.
The handshake establishes a shared session key that is then used to secure messages and provide message integrity.
Sessions are temporary, and once ended, must be re-established or resumed.
This is just a surface-level skim of the very complex cryptographic systems that help to keep your communications secure. For more depth on the topic, I recommend exploring cipher suites and the various supported algorithms.
The TLS protocol serves a very important purpose in your everyday life. It helps to secure your emails to family, your online banking activities, and the connection by which you’re reading this article. The HTTPS communication protocol is encrypted using TLS. Every time you see that little lock icon in your URL bar, you’re experiencing firsthand all the concepts you’ve just read about in this article. Now you know the answer to the last question: “How can we communicate securely?”
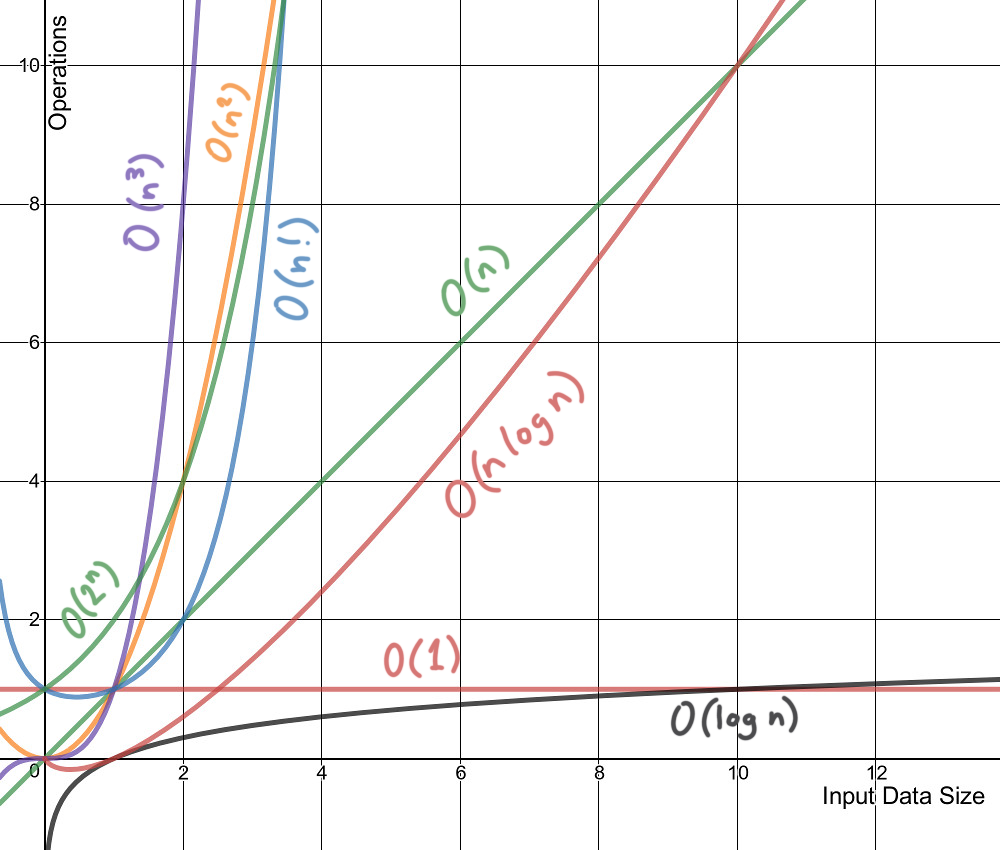
]]>A coffee-break introduction to time complexity of algorithmshttps://victoria.dev/blog/a-coffee-break-introduction-to-time-complexity-of-algorithms/Victoria Drake2018-05-30T14:08:28-04:002018-05-30T14:08:28-04:00Just like writing your very first for loop, understanding time complexity is an integral milestone to learning how to write efficient complex programs. Think of it as having a superpower that allows you to know exactly what type of program might be the most efficient in a particular situation - before even running a single line of code.
The fundamental concepts of complexity analysis are well worth studying. You’ll be able to better understand how the code you’re writing will interact with the program’s input, and as a result, you’ll spend a lot less wasted time writing slow and problematic code. It won’t take long to go over all you need to know in order to start writing more efficient programs - in fact, we can do it in about fifteen minutes. You can go grab a coffee right now (or tea, if that’s your thing) and I’ll take you through it before your coffee break is over. Go ahead, I’ll wait.
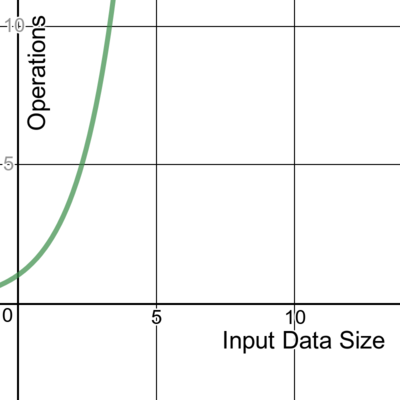
The time complexity of an algorithm is an approximation of how long that algorithm will take to process some input. It describes the efficiency of the algorithm by the magnitude of its operations. This is different than the number of times an operation repeats; I’ll expand on that later. Generally, the fewer operations the algorithm has, the faster it will be.
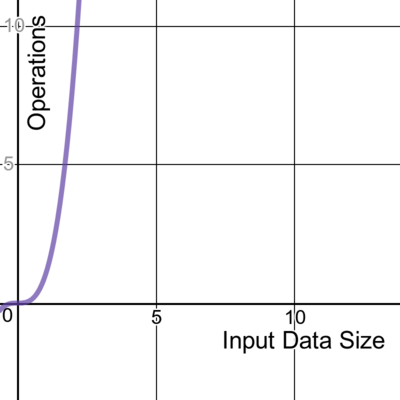
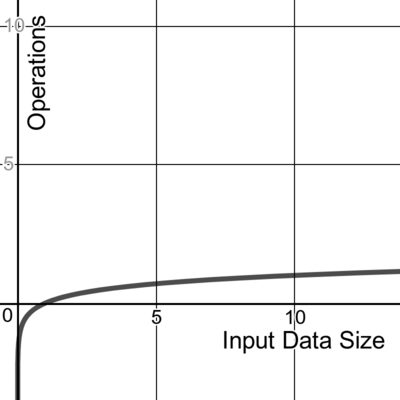
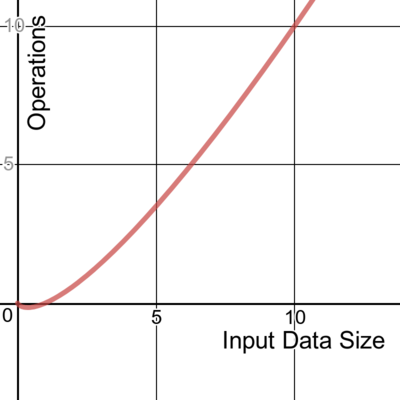
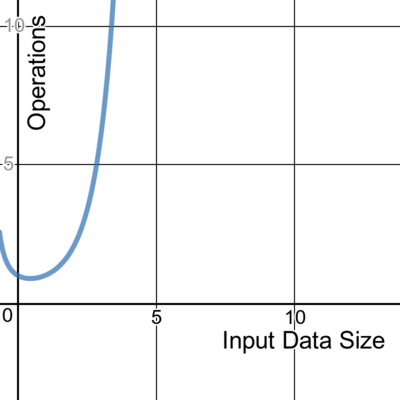
We write about time complexity using Big O notation, which looks something like O(n). There’s rather a lot of math involved in its formal definition, but informally we can say that Big O notation gives us our algorithm’s approximate run time in the worst case, or in other words, its upper bound.[2] It is inherently relative and comparative.[3] We’re describing the algorithm’s efficiency relative to the increasing size of its input data, n. If the input is a string, then n is the length of the string. If it’s a list of integers, n is the length of the list.
It’s easiest to picture what Big O notation represents with a graph:
There are different classes of complexity that we can use to quickly understand an algorithm. I’ll illustrate some of these classes using nested loops and other examples.
A polynomial, from the Greek poly meaning “many,” and Latin nomen meaning “name,” describes an expression comprised of constant variables, and addition, multiplication, and exponentiation to a non-negative integer power.[4] That’s a super math-y way to say that it contains variables usually denoted by letters and symbols that look like these:
The below classes describe polynomial algorithms. Some have food examples.
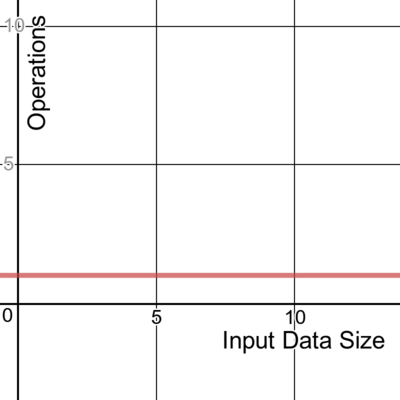
A constant time algorithm doesn’t change its running time in response to the input data. No matter the size of the data it receives, the algorithm takes the same amount of time to run. We denote this as a time complexity of O(1).
Here’s one example of a constant algorithm that takes the first item in a slice.
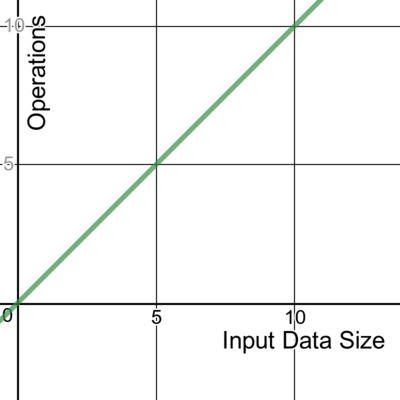
The running duration of a linear algorithm is constant. It will process the input in n number of operations. This is often the best possible (most efficient) case for time complexity where all the data must be examined.
Here’s an example of code with time complexity of O(n):
It doesn’t matter whether the code inside the loop executes once, twice, or any number of times. Both these loops process the input by a constant factor of n, and thus can be described as linear.
A logarithmic algorithm is one that reduces the size of the input at every step.
We denote this time complexity as O(log n), where log, the logarithm function, is this shape:
One example of this is a binary search algorithm that finds the position of an element within a sorted array. Here’s how it would work, assuming we’re trying to find the element x:
If x matches the middle element m of the array, return the position of m
If x doesn’t match m, see if m is larger or smaller than x
If larger, discard all array items greater than m
If smaller, discard all array items smaller than m
Continue by repeating steps 1 and 2 on the remaining array until x is found
I find the clearest analogy for understanding binary search is imagining the process of locating a book in a bookstore aisle. If the books are organized by author’s last name and you want to find “Terry Pratchett,” you know you need to look for the “P” section.
You can approach the shelf at any point along the aisle and look at the author’s last name there. If you’re looking at a book by Neil Gaiman, you know you can ignore all the rest of the books to your left, since no letters that come before “G” in the alphabet happen to be “P.” You would then move down the aisle to the right any amount, and repeat this process until you’ve found the Terry Pratchett section, which should be rather sizable if you’re at any decent bookstore because wow did he write a lot of books.
Often seen with sorting algorithms, the time complexity O(n log n) can describe a data structure where each operation takes O(log n) time. One example of this is quick sort, a divide-and-conquer algorithm.
Quick sort works by dividing up an unsorted array into smaller chunks that are easier to process. It sorts the sub-arrays, and thus the whole array. Think about it like trying to put a deck of cards in order. It’s faster if you split up the cards and get five friends to help you.
An algorithm with time complexity O(n!) often iterates through all permutations of the input elements. One common example is a brute-force search seen in the travelling salesman problem. It tries to find the least costly path between a number of points by enumerating all possible permutations and finding the ones with the lowest cost.
An exponential algorithm often also iterates through all subsets of the input elements. It is denoted O(2n) and is often seen in brute-force algorithms. It is similar to factorial time except in its rate of growth, which as you may not be surprised to hear, is exponential. The larger the data set, the more steep the curve becomes.
In cryptography, a brute-force attack may systematically check all possible elements of a password by iterating through subsets. Using an exponential algorithm to do this, it becomes incredibly resource-expensive to brute-force crack a long password versus a shorter one. This is one reason that a long password is considered more secure than a shorter one.
There are further time complexity classes less commonly seen that I won’t cover here, but you can read about these and find examples in this handy table.
As I described in my article explaining recursion using apple pie, a recursive function calls itself under specified conditions. Its time complexity depends on how many times the function is called and the time complexity of a single function call. In other words, it’s the product of the number of times the function runs and a single execution’s time complexity.
Here’s a recursive function that eats pies until no pies are left:
The time complexity of a single execution is constant. No matter how many pies are input, the program will do the same thing: check to see if the input is 0. If so, return, and if not, call itself with one fewer pie.
The initial number of pies could be any number, and we need to process all of them, so we can describe the input as n. Thus, the time complexity of this recursive function is the product O(n).
This function’s return value is zero, plus some indigestion.
So far, we’ve talked about the time complexity of a few nested loops and some code examples. Most algorithms, however, are built from many combinations of these. How do we determine the time complexity of an algorithm containing many of these elements strung together?
Easy. We can describe the total time complexity of the algorithm by finding the largest complexity among all of its parts. This is because the slowest part of the code is the bottleneck, and time complexity is concerned with describing the worst case for the algorithm’s run time.
Say we have a program for an office party. If our program looks like this:
packagemainimport"fmt"functakeCupcake(cupcakes[]int)int{fmt.Println("Have cupcake number",cupcakes[0])returncupcakes[0]}funceatChips(bowlOfChipsint){fmt.Println("Have some chips!")forchip:=0;chip<=bowlOfChips;chip++{// dip chip
}fmt.Println("No more chips.")}funcpizzaDelivery(boxesDeliveredint){fmt.Println("Pizza is here!")forpizzaBox:=0;pizzaBox<=boxesDelivered;pizzaBox++{// open box
forpizza:=0;pizza<=pizzaBox;pizza++{// slice pizza
forslice:=0;slice<=pizza;slice++{// eat slice of pizza
}}}fmt.Println("Pizza is gone.")}funceatPies(piesint)int{ifpies==0{fmt.Println("Someone ate all the pies!")returnpies}fmt.Println("Eating pie...")returneatPies(pies-1)}funcmain(){takeCupcake([]int{1,2,3})eatChips(23)pizzaDelivery(3)eatPies(3)fmt.Println("Food gone. Back to work!")}
We can describe the time complexity of all the code by the complexity of its most complex part. This program is made up of functions we’ve already seen, with the following time complexity classes:
Function
Class
Big O
takeCupcake
constant
O(1)
eatChips
linear
O(n)
pizzaDelivery
cubic
O(n3)
eatPies
linear (recursive)
O(n)
To describe the time complexity of the entire office party program, we choose the worst case. This program would have the time complexity O(n3).
Here’s the office party soundtrack, just for fun.
Have cupcake number 1Have some chips!
No more chips.
Pizza is here!
Pizza is gone.
Eating pie...
Eating pie...
Eating pie...
Someone ate all the pies!
Food gone. Back to work!
You may come across these terms in your explorations of time complexity. Informally, P (for Polynomial time), is a class of problems that is quick to solve. NP, for Nondeterministic Polynomial time, is a class of problems where the answer can be quickly verified in polynomial time. NP encompasses P, but also another class of problems called NP-complete, for which no fast solution is known.[5] Outside of NP but still including NP-complete is yet another class called NP-hard, which includes problems that no one has been able to verifiably solve with polynomial algorithms.[6]
P versus NP is an unsolved, open question in computer science.
Anyway, you don’t generally need to know about NP and NP-hard problems to begin taking advantage of understanding time complexity. They’re a whole other Pandora’s box.
So far, we’ve identified some different time complexity classes and how we might determine which one an algorithm falls into. So how does this help us before we’ve written any code to evaluate?
By combining a little knowledge of time complexity with an awareness of the size of our input data, we can take a guess at an efficient algorithm for processing our data within a given time constraint. We can base our estimation on the fact that a modern computer can perform some hundreds of millions of operations in a second.[1] The following table from the Competitive Programmer’s Handbook offers some estimates on required time complexity to process the respective input size in a time limit of one second.
Input size
Required time complexity for 1s processing time
n ≤ 10
O(n!)
n ≤ 20
O(2n)
n ≤ 500
O(n3)
n ≤ 5000
O(n2)
n ≤ 106
O(n log n) or O(n)
n is large
O(1) or O(log n)
Keep in mind that time complexity is an approximation, and not a guarantee. We can save a lot of time and effort by immediately ruling out algorithm designs that are unlikely to suit our constraints, but we must also consider that Big O notation doesn’t account for constant factors. Here’s some code to illustrate.
The following two algorithms both have O(n) time complexity.
The first function makes a cup of coffee with the number of scoops we ask for. The second function also makes a cup of coffee, but it triples the number of scoops we ask for. To see an illustrative example, let’s ask both these functions for a cup of coffee with a million scoops.
Our first function, makeCoffee, completed in an average 0.29 nanoseconds. Our second function, makeStrongCoffee, completed in an average of 0.86 nanoseconds. While those may both seem like pretty small numbers, consider that the stronger coffee took near three times longer to make. This should make sense intuitively, since we asked it to triple the scoops. Big O notation alone wouldn’t tell you this, since the constant factor of the tripled scoops isn’t accounted for.
Becoming familiar with time complexity gives us the opportunity to write code, or refactor code, to be more efficient. To illustrate, I’ll give a concrete example of one way we can refactor a bit of code to improve its time complexity.
Let’s say a bunch of people at the office want some pie. Some people want pie more than others. The amount that everyone wants some pie is represented by an int > 0:
diners:=[]int{2,88,87,16,42,10,34,1,43,56}
Unfortunately, we’re bootstrapped and there are only three forks to go around. Since we’re a cooperative bunch, the three people who want pie the most will receive the forks to eat it with. Even though they’ve all agreed on this, no one seems to want to sort themselves out and line up in an orderly fashion, so we’ll have to make do with everybody jumbled about.
Without sorting the list of diners, return the three largest integers in the slice.
Here’s a function that solves this problem and has O(n2) time complexity:
funcgiveForks(diners[]int)[]int{// make a slice to store diners who will receive forks
varwithForks[]int// loop over three forks
fori:=1;i<=3;i++{// variables to keep track of the highest integer and where it is
varmax,maxIndexint// loop over the diners slice
forn:=rangediners{// if this integer is higher than max, update max and maxIndex
ifdiners[n]>max{max=diners[n]maxIndex=n}}// remove the highest integer from the diners slice for the next loop
diners=append(diners[:maxIndex],diners[maxIndex+1:]...)// keep track of who gets a fork
withForks=append(withForks,max)}returnwithForks}
This program works, and eventually returns diners [88 87 56]. Everyone gets a little impatient while it’s running though, since it takes rather a long time (about 120 nanoseconds) just to hand out three forks, and the pie’s getting cold. How could we improve it?
By thinking about our approach in a slightly different way, we can refactor this program to have O(n) time complexity:
funcgiveForks(diners[]int)[]int{// make a slice to store diners who will receive forks
varwithForks[]int// create variables for each fork
varfirst,second,thirdint// loop over the diners
fori:=rangediners{// assign the forks
ifdiners[i]>first{third=secondsecond=firstfirst=diners[i]}elseifdiners[i]>second{third=secondsecond=diners[i]}elseifdiners[i]>third{third=diners[i]}}// list the final result of who gets a fork
withForks=append(withForks,first,second,third)returnwithForks}
Here’s how the new program works:
Initially, diner 2 (the first in the list) is assigned the first fork. The other forks remain unassigned.
Then, diner 88 is assigned the first fork instead. Diner 2 gets the second one.
Diner 87 isn’t greater than first which is currently 88, but it is greater than 2 who has the second fork. So, the second fork goes to 87. Diner 2 gets the third fork.
Continuing in this violent and rapid fork exchange, diner 16 is then assigned the third fork instead of 2, and so on.
We can add a print statement in the loop to see how the fork assignments play out:
This program is much faster, and the whole epic struggle for fork domination is over in 47 nanoseconds.
As you can see, with a little change in perspective and some refactoring, we’ve made this simple bit of code faster and more efficient.
Well, it looks like our fifteen minute coffee break is up! I hope I’ve given you a comprehensive introduction to calculating time complexity. Time to get back to work, hopefully applying your new knowledge to write more effective code! Or maybe just sound smart at your next office party. :)
]]>Knapsack problem algorithms for my real-life carry-on knapsackhttps://victoria.dev/blog/knapsack-problem-algorithms-for-my-real-life-carry-on-knapsack/Victoria Drake2018-05-09T21:00:35-04:002018-05-09T21:00:35-04:00The knapsack problem
I’m a nomad and live out of one carry-on bag. This means that the total weight of all my worldly possessions must fall under airline cabin baggage weight limits - usually 10kg. On some smaller airlines, however, this weight limit drops to 7kg. Occasionally, I have to decide not to bring something with me to adjust to the smaller weight limit.
As a practical exercise, deciding what to leave behind (or get rid of altogether) entails laying out all my things and choosing which ones to keep. That decision is based on the item’s usefulness to me (its worth) and its weight.
This is all my stuff, and my Minaal Carry-on bag.
Being a programmer, I’m aware that decisions like this could be made more efficiently by a computer. It’s done so frequently and so ubiquitously, in fact, that many will recognize this scenario as the classic packing problem or knapsack problem. How do I go about telling a computer to put as many important items in my bag as possible while coming in at or under a weight limit of 7kg? With algorithms! Yay!
I’ll discuss two common approaches to solving the knapsack problem: one called a greedy algorithm, and another called dynamic programming (a little harder, but better, faster, stronger…).
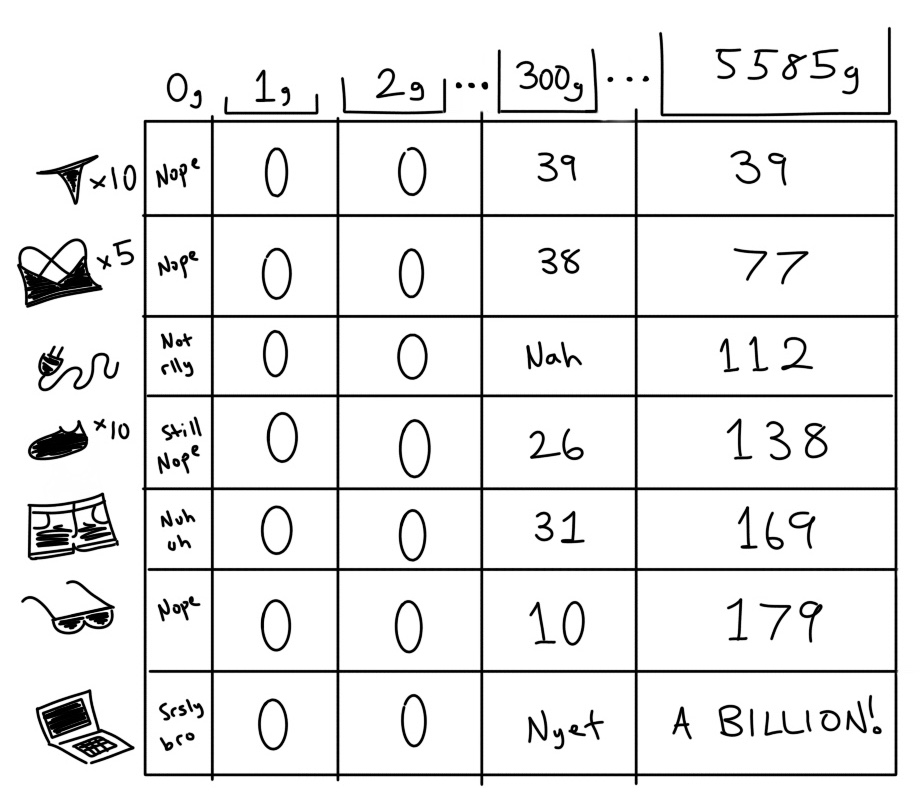
I prepared my data in the form of a CSV file with three columns: the item’s name (a string), a representation of its worth (an integer), and its weight in grams (an integer). There are 40 items in total. I represented worth by ranking each item from 40 to 1, with 40 being the most important and 1 equating with something like “why do I even have this again?” (If you’ve never listed out all your possessions and ranked them by order of how useful they are to you, I highly recommend you try it. It can be a very revealing exercise.)
Total weight of all items and bag: 9003g
Bag weight: 1415g
Airline limit: 7000g
Maximum weight of items I can pack: 5585g
Total possible worth of items: 820
The challenge: Pack as many items as the limit allows while maximizing the total worth.
Before we can begin thinking about how to solve the knapsack problem, we have to solve the problem of reading in and storing our data. Thankfully, the Go standard library’s io/ioutil package makes the first part straightforward.
The ReadFile() function takes a file path and returns the file’s contents and an error (nil if the call is successful) so we’ve also created a check() function to handle any errors that might be returned. In a real-world application we probably would want to do something more sophisticated than panic, but that’s not important right now.
Now that we’ve got our data, we should probably do something with it. Since we’re working with real-life items and a real-life bag, let’s create some types to represent them and make it easier to conceptualize our program. A struct in Go is a typed collection of fields. Here are our two types:
It is helpful to use field names that are very descriptive. You can see that the structs are set up just as we’ve described the things they represent. An item has a name (string), and a worth and weight (integers). A bag has several fields of type int representing its attributes, and also has the ability to hold items, represented in the struct as a slice of item type thingamabobbers.
Several comprehensive Go packages exist that we could use to parse our CSV data… but where’s the fun in that? Let’s go basic with some string splitting and a for loop. Here’s our updated readItems() function:
Using strings.Split, we split our dat on newlines. We then create an empty itemList to hold our items.
In our for loop, we skip the first line of our CSV file (the headers) then iterate over each line. We use strconv.Atoi (read “A to i”) to convert the values for each item’s worth and weight into integers. We then create a newItem with these field values and append it to the itemList. Finally, we return itemList.
Here’s what our set up looks like so far:
packagemainimport("io/ioutil""strconv""strings")typeitemstruct{namestringworth,weightint}typebagstruct{bagWeight,currItemsWeight,maxItemsWeight,totalWeight,totalWorthintitems[]item}funccheck(eerror){ife!=nil{panic(e)}}funcreadItems(pathstring)[]item{dat,err:=ioutil.ReadFile(path)check(err)lines:=strings.Split(string(dat),"\n")itemList:=make([]item,0)fori,v:=rangelines{ifi==0{continue// skip the headers on the first line
}s:=strings.Split(v,",")newItemWorth,_:=strconv.Atoi(s[1])newItemWeight,_:=strconv.Atoi(s[2])newItem:=item{name:s[0],worth:newItemWorth,weight:newItemWeight}itemList=append(itemList,newItem)}returnitemList}
Now that we’ve got our data structures set up, let’s get packing (🥁) on the first approach.
A greedy algorithm is the most straightforward approach to solving the knapsack problem, in that it is a one-pass algorithm that constructs a single final solution. At each stage of the problem, the greedy algorithm picks the option that is locally optimal, meaning it looks like the most suitable option right now. It does not revise its previous choices as it progresses through our data set.
The steps of the algorithm we’ll use to solve our knapsack problem are:
Sort items by worth, in descending order.
Start with the highest worth item. Put items into the bag until the next item on the list cannot fit.
Try to fill any remaining capacity with the next item on the list that can fit.
If you read my article about solving problems and making paella, you’ll know that I always start by figuring out what the next most important question is. In this case, there are three main operations we need to figure out how to do:
Sort items by worth.
Put an item in the bag.
Check to see if the bag is full.
The first one is just a docs lookup away. Here’s how we sort a slice in Go:
The sort.Slice() function orders our items according to the less function we provide. In this case, it will order the highest worth items before the lowest worth items.
Given that we don’t want to put an item in the bag if it doesn’t fit, we’ll complete the last two tasks in reverse. First, we’ll check to see if the item fits. If so, it goes in the bag.
func(b*bag)addItem(iitem)error{ifb.currItemsWeight+i.weight<=b.maxItemsWeight{b.currItemsWeight+=i.weightb.items=append(b.items,i)returnnil}returnerrors.New("could not fit item")}
Notice the * in our first line there. That indicates that bag is a pointer receiver (as opposed to a value receiver). It’s a concept that can be slightly confusing if you’re new to Go. Here are some things to consider that might help you decide when to use a value receiver and when to use a pointer receiver. For the purposes of our addItem() function, this case applies:
If the method needs to mutate the receiver, the receiver must be a pointer.
Our use of a pointer receiver tells our function we want to operate on this specific bag in particular, not a new bag. It’s important because without it, every item would always fit in a newly created bag! A little detail like this can make the difference between code that works and code that keeps you up until 4am chugging Red Bull and muttering to yourself. (Go to bed on time even if your code doesn’t work - you’ll thank me later.)
Now that we’ve got our components, let’s put together our greedy algorithm:
Then in our main() function, we’ll create our bag, read in our data, and call our greedy algorithm. Here’s what it looks like, all set up and ready to go:
So how does this algorithm do when it comes to efficiently packing our bag to maximize its total worth? Here’s the result:
Total weight of bag and items: 6987g
Total worth of packed items: 716
Here are the items our greedy algorithm chose, sorted by worth:
Item
Worth
Weight
Lenovo X1 Carbon (5th Gen)
40
112
10 pairs thongs
39
80
5 Underarmour Strappy
38
305
1 pair Uniqlo leggings
37
185
2 Lululemon Cool Racerback
36
174
Chargers and cables in Mini Bomber Travel Kit
35
665
The Roost Stand
34
170
ThinkPad Compact Bluetooth Keyboard with trackpoint
33
460
Seagate Backup PlusSlim
32
159
1 pair black denim shorts
31
197
2 pairs Nike Pro shorts
30
112
2 pairs Lululemon shorts
29
184
Isabella T-Strap Croc sandals
28
200
2 Underarmour HeatGear CoolSwitch tank tops
27
138
5 pairs black socks
26
95
2 pairs Injinji Women’s Run Lightweight No-Show Toe Socks
25
54
1 fancy tank top
24
71
1 light and stretchylong-sleeve shirt (Gap Fit)
23
147
Uniqlo Ultralight Down insulating jacket
22
235
Patagonia Torrentshell
21
301
Lightweight Merino Wool Buff
20
50
1 LBD (H&M)
19
174
Field Notes Pitch Black Memo Book Dot-Graph
18
68
Innergie PocketCell USB-C 6000mAh power bank
17
14
JBL Reflect Mini Bluetooth Sport Headphones
13
14
Oakley Latch Sunglasses
11
30
Petzl E+LITE Emergency Headlamp
8
27
It’s clear that the greedy algorithm is a straightforward way to quickly find a feasible solution. For small data sets, it will probably be close to the optimal solution. The algorithm packed a total item worth of 716 (104 points less than the maximum possible value), while filling the bag with just 13g left over.
As we learned earlier, the greedy algorithm doesn’t improve upon the solution it returns. It simply adds the next highest worth item it can to the bag.
Let’s look at another method for solving the knapsack problem that will give us the optimal solution - the highest possible total worth under the weight limit.
The name “dynamic programming” can be a bit misleading. It’s not a style of programming, as the name might cause you to infer, but simply another approach.
Dynamic programming differs from the straightforward greedy algorithm in a few key ways. Firstly, a dynamic programming bag packing solution enumerates the entire solution space with all possibilities of item combinations that could be used to pack our bag. Where a greedy algorithm chooses the most optimal local solution, dynamic programming algorithms are able to find the most optimal global solution.
Secondly, dynamic programming uses memoization to store the results of previously computed operations and returns the cached result when the operation occurs again. This allows it to “remember” previous combinations. This takes less time than it would to re-compute the answer again.
To use dynamic programming to find the optimal recipe for packing our bag, we’ll need to:
Create a matrix representing all subsets of the items (the solution space) with rows representing items and columns representing the bag’s remaining weight capacity
Loop through the matrix and calculate the worth that can be obtained by each combination of items at each stage of the bag’s capacity
Examine the completed matrix to determine which items to add to the bag in order to produce the maximum possible worth for the bag in total
It will be most helpful to visualize our solution space. Here’s a representation of what we’re building with our code:
The empty knapsackian multiverse.
In Go, we can create this matrix as a slice of slices.
We’ve padded the rows and columns by 1 so that the indicies match the item and weight numbers.
Now that we’ve created our matrix, we’ll fill it by looping over the rows and the columns:
// loop through table rows
fori:=1;i<=numItems;i++{// loop through table columns
forw:=1;w<=capacity;w++{// do stuff in each element
}}
Then for each element, we’ll calculate the worth value to ascribe to it. We do this with code that represents the following:
If the item at the index matching the current row fits within the weight capacity represented by the current column, take the maximum of either:
The total worth of the items already in the bag or,
The total worth of all the items in the bag except the item at the previous row index, plus the new item’s worth
In other words, as our algorithm considers one of the items, we’re asking it to decide whether this item added to the bag would produce a higher total worth than the last item it added to the bag, at the bag’s current total weight. If this current item is a better choice, put it in - if not, leave it out.
Here’s the code that accomplishes this:
// if weight of item matching this index can fit at the current capacity column...
ifis[i-1].weight<=w{// worth of this subset without this item
valueOne:=float64(matrix[i-1][w])// worth of this subset without the previous item, and this item instead
valueTwo:=float64(is[i-1].worth+matrix[i-1][w-is[i-1].weight])// take maximum of either valueOne or valueTwo
matrix[i][w]=int(math.Max(valueOne,valueTwo))// if the new worth is not more, carry over the previous worth
}else{matrix[i][w]=matrix[i-1][w]}
This process of comparing item combinations will continue until every item has been considered at every possible stage of the bag’s increasing total weight. When all the above have been considered, we’ll have enumerated the solution space - filled the matrix - with all possible total worth values.
We’ll have a big chart of numbers, and in the last column at the last row we’ll have our highest possible value.
A strictly representative representation of the filled matrix.
That’s great, but how do we find out which combination of items were put in the bag to achieve that worth?
To see which items combine to create our optimal packing list, we’ll need to examine our matrix in reverse to the way we created it. Since we know the highest possible value is in the last row in the last column, we’ll start there. To find the items, we:
Get the value of the current cell
Compare the value of the current cell to the value in the cell directly above it
If the values differ, there was a change to the bag items; find the next cell to examine by moving backwards through the columns according to the current item’s weight (find the value of the bag before this current item was added)
If the values match, there was no change to the bag items; move up to the cell in the row above and repeat
The nature of the action we’re trying to achieve lends itself well to a recursive function. If you recall from my previous article about making apple pie, recursive functions are simply functions that call themselves under certain conditions. Here’s what it looks like:
Our checkItem() function calls itself if the condition we described in step 4 is true. If step 3 is true, it also calls itself, but with different arguments.
Recursive functions require a base case. In this example, we want the function to stop once we run out of values of worth to compare. Thus our base case is when either i or w are 0.
Here’s how the dynamic programming approach looks when it’s all put together:
funccheckItem(b*bag,iint,wint,is[]item,matrix[][]int){ifi<=0||w<=0{return}pick:=matrix[i][w]ifpick!=matrix[i-1][w]{b.addItem(is[i-1])checkItem(b,i-1,w-is[i-1].weight,is,matrix)}else{checkItem(b,i-1,w,is,matrix)}}funcdynamic(is[]item,b*bag)*bag{numItems:=len(is)// number of items in knapsack
capacity:=b.maxItemsWeight// capacity of knapsack
// create the empty matrix
matrix:=make([][]int,numItems+1)// rows representing items
fori:=rangematrix{matrix[i]=make([]int,capacity+1)// columns representing grams of weight
}// loop through table rows
fori:=1;i<=numItems;i++{// loop through table columns
forw:=1;w<=capacity;w++{// if weight of item matching this index can fit at the current capacity column...
ifis[i-1].weight<=w{// worth of this subset without this item
valueOne:=float64(matrix[i-1][w])// worth of this subset without the previous item, and this item instead
valueTwo:=float64(is[i-1].worth+matrix[i-1][w-is[i-1].weight])// take maximum of either valueOne or valueTwo
matrix[i][w]=int(math.Max(valueOne,valueTwo))// if the new worth is not more, carry over the previous worth
}else{matrix[i][w]=matrix[i-1][w]}}}checkItem(b,numItems,capacity,is,matrix)// add other statistics to the bag
b.totalWorth=matrix[numItems][capacity]b.totalWeight=b.bagWeight+b.currItemsWeightreturnb}
We expect that the dynamic programming approach will give us a more optimized solution than the greedy algorithm. So did it? Here are the results:
Total weight of bag and items: 6982g
Total worth of packed items: 757
Here are the items our dynamic programming algorithm chose, sorted by worth:
Item
Worth
Weight
10 pairs thongs
39
80
5 Underarmour Strappy
38
305
1 pair Uniqlo leggings
37
185
2 Lululemon Cool Racerback
36
174
Chargers and cables in Mini Bomber Travel Kit
35
665
The Roost Stand
34
170
ThinkPad Compact Bluetooth Keyboard with trackpoint
33
460
Seagate Backup Plus Slim
32
159
1 pair black denim shorts
31
197
2 pairs Nike Pro shorts
30
112
2 pairs Lululemon shorts
29
184
Isabella T-Strap Croc sandals
28
200
2 Underarmour HeatGear CoolSwitch tank tops
27
138
5 pairs black socks
26
95
2 pairs Injinji Women’s Run Lightweight No-Show Toe Socks
25
54
1 fancy tank top
24
71
1 light and stretchy long-sleeve shirt (Gap Fit)
23
147
Uniqlo Ultralight Down insulating jacket
22
235
Patagonia Torrentshell
21
301
Lightweight Merino Wool Buff
20
50
1 LBD (H&M)
19
174
Field Notes Pitch Black Memo Book Dot-Graph
18
68
Innergie PocketCell USB-C 6000mAh power bank
17
148
Important papers
16
228
Deuter First Aid Kit Active
15
144
Stanley Classic Vacuum Camp Mug 16oz
14
454
JBL Reflect Mini Bluetooth Sport Headphones
13
14
Anker SoundCore nano Bluetooth Speaker
12
80
Oakley Latch Sunglasses
11
30
Ray Ban Wayfarer Classic
10
45
Petzl E+LITE Emergency Headlamp
8
27
Peak Design Cuff Camera Wrist Strap
6
26
Travelon Micro Scale
5
125
Humangear GoBites Duo
3
22
There’s an obvious improvement to our dynamic programming solution over what the greedy algorithm gave us. Our total worth of 757 is 41 points greater than the greedy algorithm’s solution of 716, and for a few grams less weight too!
While testing my dynamic programming solution, I implemented the Fisher-Yates shuffle algorithm on the input before passing it into my function, just to ensure that the answer wasn’t somehow dependent on the sort order of the input. Here’s what the shuffle looks like in Go:
As it turns out, in a way, the answer did depend on the order of the input. When I ran my dynamic programming algorithm several times, I sometimes saw a different total weight for the bag, though the total worth remained at 757. I initially thought this was a bug before examining the two sets of items that accompanied the two different total weight values. Everything was the same except for a few changes that collectively added up to a different item subset accounting for 14 of the 757 worth points.
In this case, there were two equally optimal solutions based only on the success metric of the highest total possible worth. Shuffling the input seemed to affect the placement of the items in the matrix and thus, the path that the checkItem() function took as it went through the matrix to find the chosen items. Since the success metric of having the highest possible worth was the same in both item sets, we don’t have a single unique solution - there’s two!
As an academic exercise, both these sets of items are correct answers. We may choose to optimize further by another metric, say, the total weight of all the items. The highest possible worth at the least possible weight could be seen as an ideal solution.
Here’s the second, lighter, dynamic programming result:
Total weight of bag and items: 6955g
Total worth of packed items: 757
Item
Worth
Weight
10 pairs thongs
39
80
5 Underarmour Strappy
38
305
1 pair Uniqlo leggings
37
185
2 Lululemon Cool Racerback
36
174
Chargers and cables in Mini Bomber Travel Kit
35
665
The Roost Stand
34
170
ThinkPad Compact Bluetooth Keyboard with trackpoint
33
460
Seagate Backup Plus Slim
32
159
1 pair black denim shorts
31
197
2 pairs Nike Pro shorts
30
112
2 pairs Lululemon shorts
29
184
Isabella T-Strap Croc sandals
28
200
2 Underarmour HeatGear CoolSwitch tank tops
27
138
5 pairs black socks
26
95
2 pairs Injinji Women’s Run Lightweight No-Show Toe Socks
The Go standard library’s testing package makes it straightforward for us to benchmark these two approaches. We can find out how long it takes each algorithm to run, and how much memory each uses. Here’s a simple main_test.go file:
After running the greedy algorithm 1,000,000 times, the speed of the algorithm was reliably measured to be 0.001619 milliseconds (translation: very fast). It required 2128 Bytes or 2-ish kilobytes of memory and 9 distinct memory allocations per iteration.
The dynamic programming algorithm was run 1,000 times. Its speed was measured to be 1.545322 milliseconds or 0.001545322 seconds (translation: still pretty fast). It required 2,020,332 Bytes or 2-ish Megabytes, and 49 distinct memory allocations per iteration.
Part of choosing the right approach to solving any programming problem is taking into account the size of the input data set. In this case, it’s a small one. In this scenario, a one-pass greedy algorithm will always be faster and less resource-needy than dynamic programming, simply because it has fewer steps. Our greedy algorithm was almost two orders of magnitude faster and less memory-hungry than our dynamic programming algorithm.
Not having those extra steps, however, means that getting the best possible solution from the greedy algorithm is unlikely.
It’s clear that the dynamic programming algorithm gave us better numbers: a lower weight, and higher overall worth.
Greedy algorithm
Dynamic programming
Total weight:
6987g
6955g
Total worth:
716
757
Where dynamic programming on small data sets lacks in performance, it makes up in optimization. The question then becomes whether that additional optimization is worth the performance cost.
“Better,” of course, is a subjective judgement. If speed and low resource usage is our success metric, then the greedy algorithm is clearly better. If the total worth of items in the bag is our success metric, then dynamic programming is clearly better. However, our scenario is a practical one, and only one of these algorithm designs returned an answer I’d choose. In optimizing for the overall greatest possible total worth of the items in the bag, the dynamic programming algorithm left out my highest-worth, but also heaviest, item: my laptop. The chargers and cables, Roost stand, and keyboard that were included aren’t much use without it.
There’s a simple way to alter the dynamic programming approach so that the laptop is always included: we can modify the data so that the worth of the laptop is greater than the sum of the worth of all the other items. (Try it out!)
Perhaps in re-designing the dynamic programming algorithm to be more practical, we might choose another success metric that better reflects an item’s importance, instead of a subjective worth value. There are many possible metrics we can use to represent the value of an item. Here are a few examples of a good proxy:
Amount of time spent using the item
Initial cost of purchasing the item
Cost of replacement if the item were lost today
Dollar value of the product of using the item
By the same token, the greedy algorithm’s results might be improved with the use of one of these alternate metrics.
On top of choosing an appropriate approach to solving the knapsack problem in general, it is helpful to design our algorithm in a way that translates the practicalities of a scenario into code.
There are many considerations for better algorithm design beyond the scope of this introductory post. One of these is time complexity, and I’ve written about it here. A future algorithm may very well decide my bag’s contents on the next trip, but we’re not quite there yet. Stay tuned!
]]>A Unicode substitution cipher algorithmhttps://victoria.dev/blog/a-unicode-substitution-cipher-algorithm/Victoria Drake2018-01-06T20:00:28-05:002018-01-06T20:00:28-05:00Full transparency: I occasionally waste time messing around on Twitter. (Gasp! Shock!) One of the ways I waste time messing around on Twitter is by writing my name in my profile with different Unicode character “fonts,” 𝖑𝖎𝖐𝖊 𝖙𝖍𝖎𝖘 𝖔𝖓𝖊. I previously did this by searching for different Unicode characters on Google, then one-by-one copying and pasting them into the “Name” field on my Twitter profile. Since this method of wasting time was a bit of a time waster, I decided (in true programmer fashion) to write a tool that would help me save some time while wasting it.
I originally dubbed the tool “uni-pretty,” (based on LEGO’s Unikitty from a movie – a pun that absolutely no one got) but have since renamed it fancy unicode. It builds from this GitHub repo. It lets you type any characters into a field and then converts them into Unicode characters that also represent letters, giving you fancy “fonts” that override a website’s CSS, like in your Twitter profile. (Sorry, Internet.)
The tool’s first naive iteration existed for about twenty minutes while I copy-pasted Unicode characters into a data structure. This approach of storing the characters in the JavaScript file, called hard-coding, is fraught with issues. Besides having to store every character from every font style, it’s painstaking to build, hard to update, and more code means it’s susceptible to more possible errors.
Fortunately, working with Unicode means that there’s a way to avoid the whole mess of having to store all the font characters: Unicode numbers are sequential. More importantly, the special characters in Unicode that could be used as fonts (meaning that there’s a matching character for most or all of the letters of the alphabet) are always in the following sequence: capital A-Z, lowercase a-z.
For example, in the fancy Unicode above, the lowercase letter “L” character has the Unicode number U+1D591 and HTML code 𝖑. The next letter in the sequence, a lowercase letter “M,” has the Unicode number U+1D592 and HTML code 𝖒. Notice how the numbers in those codes increment by one.
Why’s this relevant? Since each special character can be referenced by a number, and we know that the order of the sequence is always the same (capital A-Z, lowercase a-z), we’re able to produce any character simply by knowing the first number of its font sequence (the capital “A”). If this reminds you of anything, you can borrow my decoder pin.
In cryptography, the Caesar cipher (or shift cipher) is a simple method of encryption that utilizes substitution of one character for another in order to encode a message. This is typically done using the alphabet and a shift “key” that tells you which letter to substitute for the original one. For example, if I were trying to encode the word “cat” with a right shift of 3, it would look like this:
c a t
f d w
With this concept, encoding our plain text letters as a Unicode “font” is a simple process. All we need is an array to reference our plain text letters with, and the first index of our Unicode capital “A” representation. Since some Unicode numbers also include letters (which are sequential, but an unnecessary complication) and since the intent is to display the page in HTML, we’ll use the HTML code number 𝕬, with the extra bits removed for brevity.
Since we know that the letter sequence of the fancy Unicode is the same as our plain text array, any letter can be found by using its index in the plain text array as an offset from the fancy capital “A” number. For example, capital “B” in fancy Unicode is the capital “A” number, 120172 plus B’s index, which is 1: 120173.
Here’s our conversion function:
functionconvert(string){// Create a variable to store our converted letters
letconverted=[];// Break string into substrings (letters)
letarr=string.split('');// Search plain array for indexes of letters
arr.forEach(element=>{leti=plain.indexOf(element);// If the letter isn't a letter (not found in the plain array)
if(i==-1){// Return as a whitespace
converted.push(' ');}else{// Get relevant character from fancy number + index
letunicode=fancyA+i;// Return as HTML code
converted.push('&#'+unicode+';');}});// Print the converted letters as a string
console.log(converted.join(''));}
A neat possibility for this method of encoding requires a departure from my original purpose, which was to create a human-readable representation of the original string. If the purpose was instead to produce a cipher, this could be done by using any Unicode index in place of fancyA as long as the character indexed isn’t a representation of a capital “A.”
Here’s the same code set up with a simplified plain text array, and a non-letter-representation Unicode key:
You might be able to imagine that decoding a cipher produced by this method would be relatively straightforward, once you knew the encoding secret. You’d simply need to subtract the key from the HTML code numbers of the encoded characters, then find the relevant plain text letters at the remaining indexes.
Well, that’s it for today. Be sure to drink your Ovaltine and we’ll see you right here next Monday at 5:45!
]]>How to code a satellite algorithm and cook paella from scratchhttps://victoria.dev/blog/how-to-code-a-satellite-algorithm-and-cook-paella-from-scratch/Victoria Drake2017-09-08T16:50:24-04:002017-09-08T16:50:24-04:00What if I told you that by the end of this article, you’ll be able to calculate the orbital period of satellites around Earth using their average altitudes and… You tuned out already, didn’t you?
Okay, how about this: I’m going to teach you how to make paella!
And you’ll have written a function that does the stuff I mentioned above, just like I did for a freeCodeCamp challenge.
I promise there’s an overarching moral lesson that will benefit you every day for the rest of your life. Or at least, feed you for one night. Let’s get started.
Unless you’re reading this on a Samsung phone, in which case you’re looking at a Korean hotpot.
One of my favorite things about living in the world today is that it’s totally fine to know next-to-nothing about something. A hundred years ago you might have gone your whole life not knowing anything more about paella other than that it’s an emoticon.* But today? You can simply look it up.
*That was a joke.
As with all things in life, when we are unsure, we turn to the internet - in this case, the entry for paella on Wikipedia, which reads:
Paella …is a Valencian rice dish. Paella has ancient roots, but its modern form originated in the mid-19th century near the Albufera lagoon on the east coast of Spain adjacent to the city of Valencia. Many non-Spaniards view paella as Spain’s national dish, but most Spaniards consider it to be a regional Valencian dish. Valencians, in turn, regard paella as one of their identifying symbols.
At this point, you’re probably full of questions. Do I need to talk to a Valencian? Should I take an online course on the history of Spain? What type of paella should I try to make? What is the common opinion of modern chefs when it comes to paella types?
If you set out with the intention of answering all these questions, one thing is certain: you’ll never end up actually making paella. You’ll spend hours upon hours typing questions into search engines and years later wake up with a Masters in Valencian Cuisine.
When I talk to myself out loud in public (doesn’t everyone?) I refer to this as “MIQ” (rhymes with “Nick”). I also imagine MIQ to be a rather crunchy and quite adorable anthropomorphized tortilla chip. Couldn’t tell you why.
MIQ swings his crunchy triangular body around to point me in the right direction, and the right direction always takes the form of the most important question that you need to ask yourself at any stage of problem solving. The first most important question is always this:
What is the scope of the objective I want to achieve?
Well, you want to make paella.
The next MIQ then becomes: how much do I actually need to know about paella in order to start making it?
You’ve heard this advice before: any big problem can be broken down into multiple, but more manageable, bite-size problems. In this little constellation of bite-size problems, there’s only one that you need to solve in order to get most of the way to a complete solution.
In the case of making paella, we need a recipe. That’s a bite-size problem that a search engine can solve for us:
Simple Paella Recipe
In a medium bowl, mix together 2 tablespoons olive oil, paprika, oregano, and salt and pepper. Stir in chicken pieces to coat. Cover, and refrigerate.
Heat 2 tablespoons olive oil in a large skillet or paella pan over medium heat. Stir in garlic, red pepper flakes, and rice. Cook, stirring, to coat rice with oil, about 3 minutes. Stir in saffron threads, bay leaf, parsley, chicken stock, and lemon zest. Bring to a boil, cover, and reduce heat to medium low. Simmer 20 minutes.
Meanwhile, heat 2 tablespoons olive oil in a separate skillet over medium heat. Stir in marinated chicken and onion; cook 5 minutes. Stir in bell pepper and sausage; cook 5 minutes. Stir in shrimp; cook, turning the shrimp, until both sides are pink.
Spread rice mixture onto a serving tray. Top with meat and seafood mixture. (allrecipes.com)
And voila! Believe it or not, we’re most of the way there already.
Having a set of step-by-step instructions that are easy to understand is really most of the work done. All that’s left is to go through the motions of gathering the ingredients and then making paella. From this point on, your MIQs may become fewer and far between, and they may slowly decrease in importance in relation to the overall problem. (Where do I buy paprika? How do I know when sausage is cooked? How do I set the timer on my phone for 20 minutes? How do I stop thinking about this delicious smell? Which Instagram filter best captures the ecstasy of this paella right now?)
Well, as it turns out, in order to calculate the orbital period of satellites, we also need a recipe. Amazing, the things you can find on the internet these days.
Courtesy of dummies.com (yup! #noshame), here’s our recipe:
It’s kind of cute, in a way.
That might look pretty complicated, but as we’ve already seen, we just need to answer the next MIQ: how much do I actually need to know about this formula in order to start using it?
In the case of this challenge, not too much. We’re already given earthRadius, and avgAlt is part of our arguments object. Together, they form the radius, r. With a couple search queries and some mental time-travel to your elementary math class, we can describe this formula in a smattering of English:
T, the orbital period, equals 2 multiplied by Pi, in turn multiplied by the square root of the radius, r cubed, divided by the gravitational mass, GM.
JavaScript has a Math.PI property, as well as Math.sqrt() function and Math.pow() function. Using those combined with simple calculation, we can represent this equation in a single line assigned to a variable:
Believe it or not, we’re already most of the way there.
The next MIQ for this challenge is to take the arguments object, extract the information we need, and return the result of our equation in the required format. There are a multitude of ways to do this, but I’m happy with a straightforward for loop:
Don’t look now, but you just gained the ability to calculate the orbital period of satellites. You could even do it while making paella, if you wanted to. Seriously. Put it on your resume.
Whether it’s cooking, coding, or anything else, problems may at first seem confusing, insurmountable, or downright boring. If you’re faced with such a challenge, just remember: they’re a lot more digestible with a side of bite-sized MIQ chips.